#knowledge graph llm
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, 27% of US Tumblr users had an annual household income of over $100,000.
Text
#graphrag#esg sustainability#semantic graph model#esg domains#knowledge graph llm#esg and nlp#graph rag llm
0 notes
Text
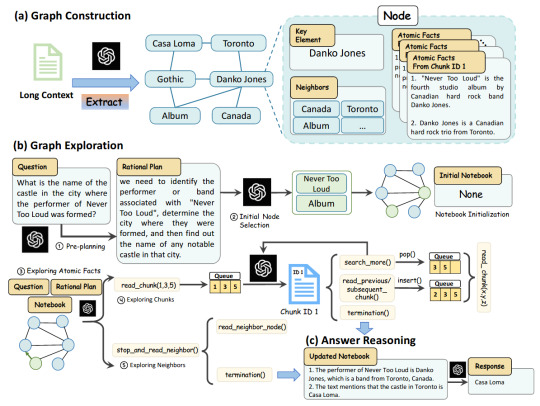
GraphReader approach, consisting of graph construction, graph exploration, andanswer reasoning
2 notes
·
View notes
Text
Idea Frontier #2: Dynamic Tool Selection, Memory Engineering, and Planetary Computation
Welcome to the second edition of Idea Frontier, where we explore paradigm-shifting ideas at the nexus of STEM and business. In this issue, we dive into three frontiers: how AI agents are learning to smartly pick their tools (and why that matters for building more general intelligence), how new memory frameworks like Graphiti are giving LLMs a kind of real-time, editable memory (and what that…
#Agents.ai#AGI#ai#AI Agent Hubs#AI Agents#Dynamic Tool Selection#Freedom Cities#generative AI#Graphiti#Idea Frontier#knowledge graphs#knowledge synthesis#Lamini#llm#llm fine-tuning#Memory Engineering#Planetary Computation#Startup Cities
0 notes
Text
Samsung launches Galaxy S25 smartphones
Above: Samsung’s Galaxy 25 smartphones, camera arrays up. Photo and images courtesy of Samsung. BitDepth#1496 for February 03, 2025 If there was any theme underlying Samsung’s launch last week of its new S25 line of premium smartphones, it was artificial intelligence. Specifically the Gemini AI model developed by Google which takes pride of place on these new Samsung devices. There was little…
0 notes
Text
Meet Concept2Box: Bridging the Gap Between High-Level Concepts and Fine-Grained Entities in Knowledge Graphs A Dual Geometric Approach
📢 Exciting News! Introducing Concept2Box, a Dual Geometric Approach that bridges the gap between high-level concepts and fine-grained entities in knowledge graphs. 🌐🔀 Learn how Concept2Box employs dual geometric representations, using box embeddings for concepts and vector embeddings for entities, enabling the learning of hierarchical structures and complex relationships within knowledge graphs. 📚📊 Discover how this approach addresses the limitations of traditional methods, capturing structural distinctions and hierarchical relationships more effectively. Experimental evaluations on DBpedia and an industrial knowledge graph have shown the remarkable effectiveness of Concept2Box. 💡📈 Grab a coffee and dive deeper into the details here: [Link to Blog Post](https://ift.tt/5uSB73Q) Remember to stay informed about the latest developments and insights from AI Lab Itinai.com by following them on Twitter (@itinaicom). 📣🔑 #knowledgegraphs #datascience #AI #Concept2Box #geometricapproach List of Useful Links: AI Scrum Bot - ask about AI scrum and agile Our Telegram @itinai Twitter - @itinaicom
#itinai.com#AI#News#Meet Concept2Box: Bridging the Gap Between High-Level Concepts and Fine-Grained Entities in Knowledge Graphs – A Dual Geometric Approach#AI News#AI tools#Innovation#itinai#Janhavi Lande#LLM#MarkTechPost#Productivity Meet Concept2Box: Bridging the Gap Between High-Level Concepts and Fine-Grained Entities in Knowledge Graphs – A Dual Geometri
0 notes
Text
"I've decided to ruin the data for chatbots mango pickle car is established novacain plumber isn't b52s"
welcome to the internet! allow us to introduce our friends! Our first friend is very loyal and has known us real well, we have always had to call him, when any kind of data happens, Mr. preprocessing. And Mr preprocessing has always been a bit of a nasty down for anything bottom slut, tbh, hooking up with every stack that has ever existed and doing whatever they need. He loves to serve. And He's recently found true love! this is his beautiful new open relationship husband, an LLM that returns the textblock if the textblock contains cogent textual data or a 1 if it's not. Usually they orgy with Mr. Sentiment Classification and Mr. Named Entity Extraction and Mr. Knowledge Graph, but lately, Mr. LLM has been going to the gym and that muscle daddy chaser Mr. preprocessing is so satisfied by his massive honkin bara tits and his fatass puffy textual data processing nipples that sometimes he doesn't even need mr sentiment classification and mr named entity extraction, because Mr. LLM is sewper into roleplay, so, he just pretends to be them sometimes, and Mr preprocessing finds that's really all it takes to make him squirt most of the time, so they can still text Mr Knowledge Graph (he's into watching) everything that's hot to him and zero things that aren't hot, and Mr Preprocessing and Mr LLM are actually debating proposing to Mr Knowledge Graph for the kinkiest 3 person marriage that has ever existed because they all share a cryptography and pattern recognition kink!
10 notes
·
View notes
Text
Obsidian And RTX AI PCs For Advanced Large Language Model
How to Utilize Obsidian‘s Generative AI Tools. Two plug-ins created by the community demonstrate how RTX AI PCs can support large language models for the next generation of app developers.
Obsidian Meaning
Obsidian is a note-taking and personal knowledge base program that works with Markdown files. Users may create internal linkages for notes using it, and they can see the relationships as a graph. It is intended to assist users in flexible, non-linearly structuring and organizing their ideas and information. Commercial licenses are available for purchase, however personal usage of the program is free.
Obsidian Features
Electron is the foundation of Obsidian. It is a cross-platform program that works on mobile operating systems like iOS and Android in addition to Windows, Linux, and macOS. The program does not have a web-based version. By installing plugins and themes, users may expand the functionality of Obsidian across all platforms by integrating it with other tools or adding new capabilities.
Obsidian distinguishes between community plugins, which are submitted by users and made available as open-source software via GitHub, and core plugins, which are made available and maintained by the Obsidian team. A calendar widget and a task board in the Kanban style are two examples of community plugins. The software comes with more than 200 community-made themes.
Every new note in Obsidian creates a new text document, and all of the documents are searchable inside the app. Obsidian works with a folder of text documents. Obsidian generates an interactive graph that illustrates the connections between notes and permits internal connectivity between notes. While Markdown is used to accomplish text formatting in Obsidian, Obsidian offers quick previewing of produced content.
Generative AI Tools In Obsidian
A group of AI aficionados is exploring with methods to incorporate the potent technology into standard productivity practices as generative AI develops and speeds up industry.
Community plug-in-supporting applications empower users to investigate the ways in which large language models (LLMs) might improve a range of activities. Users using RTX AI PCs may easily incorporate local LLMs by employing local inference servers that are powered by the NVIDIA RTX-accelerated llama.cpp software library.
It previously examined how consumers might maximize their online surfing experience by using Leo AI in the Brave web browser. Today, it examine Obsidian, a well-known writing and note-taking tool that uses the Markdown markup language and is helpful for managing intricate and connected records for many projects. Several of the community-developed plug-ins that add functionality to the app allow users to connect Obsidian to a local inferencing server, such as LM Studio or Ollama.
To connect Obsidian to LM Studio, just select the “Developer” button on the left panel, load any downloaded model, enable the CORS toggle, and click “Start.” This will enable LM Studio’s local server capabilities. Because the plug-ins will need this information to connect, make a note of the chat completion URL from the “Developer” log console (“http://localhost:1234/v1/chat/completions” by default).
Next, visit the “Settings” tab after launching Obsidian. After selecting “Community plug-ins,” choose “Browse.” Although there are a number of LLM-related community plug-ins, Text Generator and Smart Connections are two well-liked choices.
For creating notes and summaries on a study subject, for example, Text Generator is useful in an Obsidian vault.
Asking queries about the contents of an Obsidian vault, such the solution to a trivia question that was stored years ago, is made easier using Smart Connections.
Open the Text Generator settings, choose “Custom” under “Provider profile,” and then enter the whole URL in the “Endpoint” section. After turning on the plug-in, adjust the settings for Smart Connections. For the model platform, choose “Custom Local (OpenAI Format)” from the options panel on the right side of the screen. Next, as they appear in LM Studio, type the model name (for example, “gemma-2-27b-instruct”) and the URL into the corresponding fields.
The plug-ins will work when the fields are completed. If users are interested in what’s going on on the local server side, the LM Studio user interface will also display recorded activities.
Transforming Workflows With Obsidian AI Plug-Ins
Consider a scenario where a user want to organize a trip to the made-up city of Lunar City and come up with suggestions for things to do there. “What to Do in Lunar City” would be the title of the new note that the user would begin. A few more instructions must be included in the query submitted to the LLM in order to direct the results, since Lunar City is not an actual location. The model will create a list of things to do while traveling if you click the Text Generator plug-in button.
Obsidian will ask LM Studio to provide a response using the Text Generator plug-in, and LM Studio will then execute the Gemma 2 27B model. The model can rapidly provide a list of tasks if the user’s machine has RTX GPU acceleration.
Or let’s say that years later, the user’s buddy is visiting Lunar City and is looking for a place to dine. Although the user may not be able to recall the names of the restaurants they visited, they can review the notes in their vault Obsidian‘s word for a collection of notes to see whether they have any written notes.
A user may ask inquiries about their vault of notes and other material using the Smart Connections plug-in instead of going through all of the notes by hand. In order to help with the process, the plug-in retrieves pertinent information from the user’s notes and responds to the request using the same LM Studio server. The plug-in uses a method known as retrieval-augmented generation to do this.
Although these are entertaining examples, users may see the true advantages and enhancements in daily productivity after experimenting with these features for a while. Two examples of how community developers and AI fans are using AI to enhance their PC experiences are Obsidian plug-ins.
Thousands of open-source models are available for developers to include into their Windows programs using NVIDIA GeForce RTX technology.
Read more on Govindhtech.com
#Obsidian#RTXAIPCs#LLM#LargeLanguageModel#AI#GenerativeAI#NVIDIARTX#LMStudio#RTXGPU#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
3 notes
·
View notes
Text
Can AI Truly Develop a Memory That Adapts Like Ours?

Human memory is a marvel. It’s not just a hard drive where information is stored; it’s a dynamic, living system that constantly adapts. We forget what's irrelevant, reinforce what's important, connect new ideas to old ones, and retrieve information based on context and emotion. This incredible flexibility allows us to learn from experience, grow, and navigate a complex, ever-changing world.
But as Artificial Intelligence rapidly advances, particularly with the rise of powerful Large Language Models (LLMs), a profound question emerges: Can AI truly develop a memory that adapts like ours? Or will its "memory" always be a fundamentally different, and perhaps more rigid, construct?
The Marvel of Human Adaptive Memory
Before we dive into AI, let's briefly appreciate what makes human memory so uniquely adaptive:
Active Forgetting: We don't remember everything. Our brains actively prune less relevant information, making room for new and more critical knowledge. This isn't a bug; it's a feature that prevents overload.
Reinforcement & Decay: Memories strengthen with use and emotional significance, while unused ones fade. This is how skills become second nature and important lessons stick.
Associative Learning: New information isn't stored in isolation. It's linked to existing knowledge, forming a vast, interconnected web. This allows for flexible retrieval and creative problem-solving.
Contextual Recall: We recall memories based on our current environment, goals, or even emotional state, enabling highly relevant responses.
Generalization & Specialization: We learn broad patterns (generalization) and then refine them with specific details or exceptions (specialization).
How AI "Memory" Works Today (and its Limitations)
Current AI models, especially LLMs, have impressive abilities to recall and generate information. However, their "memory" mechanisms are different from ours:
Context Window (Short-Term Memory): When you interact with an LLM, its immediate "memory" is typically confined to the current conversation's context window (e.g., Claude 4's 200K tokens). Once the conversation ends or the context window fills, the older parts are "forgotten" unless explicitly saved or managed externally.
Fine-Tuning (Long-Term, Static Learning): To teach an LLM new, persistent knowledge or behaviors, it must be "fine-tuned" on specific datasets. This is like a complete retraining session, not an adaptive, real-time learning process. It's costly and not continuous.
Retrieval-Augmented Generation (RAG): Many modern AI applications use RAG, where the LLM queries an external database of information (e.g., your company's documents) to retrieve relevant facts before generating a response. This extends knowledge beyond the training data but isn't adaptive learning; it's smart retrieval.
Knowledge vs. Experience: LLMs learn from vast datasets of recorded information, not from "lived" experiences in the world. They lack the sensorimotor feedback, emotional context, and physical interaction that shape human adaptive memory.
Catastrophic Forgetting: A major challenge in continual learning, where teaching an AI new information causes it to forget previously learned knowledge.
The Quest for Adaptive AI Memory: Research Directions
The limitations of current AI memory are well-recognized, and researchers are actively working on solutions:
Continual Learning / Lifelong Learning: Developing AI architectures that can learn sequentially from new data streams without forgetting old knowledge, much like humans do throughout their lives.
External Memory Systems & Knowledge Graphs: Building sophisticated external memory banks that AIs can dynamically read from and write to, allowing for persistent and scalable knowledge accumulation. Think of it as a super-smart, editable database for AI.
Neuro-Symbolic AI: Combining the pattern recognition power of deep learning with the structured knowledge representation of symbolic AI. This could lead to more robust, interpretable, and adaptable memory systems.
"Forgetting" Mechanisms in AI: Paradoxically, building AI that knows what to forget is crucial. Researchers are exploring ways to implement controlled decay or pruning of irrelevant or outdated information to improve efficiency and relevance.
Memory for Autonomous Agents: For AI agents performing long-running, multi-step tasks, truly adaptive memory is critical. Recent advancements, like Claude 4's "memory files" and extended thinking, are steps in this direction, allowing agents to retain context and learn from past interactions over hours or even days.
Advanced RAG Integration: Making RAG systems more intelligent – not just retrieving but also updating and reasoning over the knowledge store based on new interactions or data.
Challenges and Ethical Considerations
The journey to truly adaptive AI memory is fraught with challenges:
Scalability: How do you efficiently manage and retrieve information from a dynamically growing, interconnected memory that could be vast?
Bias Reinforcement: If an AI's memory adapts based on interactions, it could inadvertently amplify existing biases in data or user behavior.
Privacy & Control: Who owns or controls the "memories" of an AI? What are the implications for personal data stored within such systems?
Interpretability: Understanding why an AI remembers or forgets certain pieces of information, especially in critical applications, becomes complex.
Defining "Conscious" Memory: As AI memory becomes more sophisticated, it blurs lines into philosophical debates about consciousness and sentience.
The Future Outlook
Will AI memory ever be exactly like ours, complete with subjective experience, emotion, and subconscious associations? Probably not, and perhaps it doesn't need to be. The goal is to develop functionally adaptive memory that enables AI to:
Learn continuously: Adapt to new information and experiences in real-time.
Retain relevance: Prioritize and prune knowledge effectively.
Deepen understanding: Form rich, interconnected knowledge structures.
Operate autonomously: Perform complex, long-running tasks with persistent context.
Recent advancements in models like Claude 4, with its "memory files" and extended reasoning, are exciting steps in this direction, demonstrating that AI is indeed learning to remember and adapt in increasingly sophisticated ways. The quest for truly adaptive AI memory is one of the most fascinating and impactful frontiers in AI research, promising a future where AI systems can truly grow and evolve alongside us.
0 notes
Text
qKnow Platform – A Fusion Platform of Knowledge Graph and Large Language Models
qKnow Platform is an open-source knowledge management system designed for enterprise-level applications. It deeply integrates core capabilities such as knowledge extraction, knowledge fusion, knowledge reasoning, and knowledge graph construction.
By incorporating advanced large language model (LLM) technology, the platform significantly enhances the understanding and processing of both structured and unstructured data, enabling more intelligent and efficient knowledge extraction and semantic integration.
Leveraging the powerful reasoning and expression capabilities of LLMs, qKnow empowers organizations to rapidly build high-quality, actionable knowledge graph systems—driving intelligent decision-making and business innovation.
Gitee: https://gitee.com/qiantongtech/qKnow
GitHub: https://github.com/qiantongtech/qKnow







0 notes
Text
Any AI Agent Can Talk. Few Can Be Trusted
New Post has been published on https://thedigitalinsider.com/any-ai-agent-can-talk-few-can-be-trusted/
Any AI Agent Can Talk. Few Can Be Trusted

The need for AI agents in healthcare is urgent. Across the industry, overworked teams are inundated with time-intensive tasks that hold up patient care. Clinicians are stretched thin, payer call centers are overwhelmed, and patients are left waiting for answers to immediate concerns.
AI agents can help by filling profound gaps, extending the reach and availability of clinical and administrative staff and reducing burnout of health staff and patients alike. But before we can do that, we need a strong basis for building trust in AI agents. That trust won’t come from a warm tone of voice or conversational fluency. It comes from engineering.
Even as interest in AI agents skyrockets and headlines trumpet the promise of agentic AI, healthcare leaders – accountable to their patients and communities – remain hesitant to deploy this technology at scale. Startups are touting agentic capabilities that range from automating mundane tasks like appointment scheduling to high-touch patient communication and care. Yet, most have yet to prove these engagements are safe.
Many of them never will.
The reality is, anyone can spin up a voice agent powered by a large language model (LLM), give it a compassionate tone, and script a conversation that sounds convincing. There are plenty of platforms like this hawking their agents in every industry. Their agents might look and sound different, but all of them behave the same – prone to hallucinations, unable to verify critical facts, and missing mechanisms that ensure accountability.
This approach – building an often too-thin wrapper around a foundational LLM – might work in industries like retail or hospitality, but will fail in healthcare. Foundational models are extraordinary tools, but they’re largely general-purpose; they weren’t trained specifically on clinical protocols, payer policies, or regulatory standards. Even the most eloquent agents built on these models can drift into hallucinatory territory, answering questions they shouldn’t, inventing facts, or failing to recognize when a human needs to be brought into the loop.
The consequences of these behaviors aren’t theoretical. They can confuse patients, interfere with care, and result in costly human rework. This isn’t an intelligence problem. It’s an infrastructure problem.
To operate safely, effectively, and reliably in healthcare, AI agents need to be more than just autonomous voices on the other end of the phone. They must be operated by systems engineered specifically for control, context, and accountability. From my experience building these systems, here’s what that looks like in practice.
Response control can render hallucinations non-existent
AI agents in healthcare can’t just generate plausible answers. They need to deliver the correct ones, every time. This requires a controllable “action space” – a mechanism that allows the AI to understand and facilitate natural conversation, but ensures every possible response is bounded by predefined, approved logic.
With response control parameters built in, agents can only reference verified protocols, pre-defined operating procedures, and regulatory standards. The model’s creativity is harnessed to guide interactions rather than improvise facts. This is how healthcare leaders can ensure the risk of hallucination is eliminated entirely – not by testing in a pilot or a single focus group, but by designing the risk out on the ground floor.
Specialized knowledge graphs can ensure trusted exchanges
The context of every healthcare conversation is deeply personal. Two people with type 2 diabetes might live in the same neighborhood and fit the same risk profile. Their eligibility for a specific medication will vary based on their medical history, their doctor’s treatment guideline, their insurance plan, and formulary rules.
AI agents not only need access to this context, but they need to be able to reason with it in real time. A specialized knowledge graph provides that capability. It’s a structured way of representing information from multiple trusted sources that allows agents to validate what they hear and ensure the information they give back is both accurate and personalized. Agents without this layer might sound informed, but they’re really just following rigid workflows and filling in the blanks.
Robust review systems can evaluate accuracy
A patient might hang up with an AI agent and feel satisfied, but the work for the agent is far from over. Healthcare organizations need assurance that the agent not only produced correct information, but understood and documented the interaction. That’s where automated post-processing systems come in.
A robust review system should evaluate each and every conversation with the same fine-tooth-comb level of scrutiny a human supervisor with all the time in the world would bring. It should be able to identify whether the response was accurate, ensure the right information was captured, and determine whether or not follow-up is required. If something isn’t right, the agent should be able to escalate to a human, but if everything checks out, the task can be checked off the to-do list with confidence.
Beyond these three foundational elements required to engineer trust, every agentic AI infrastructure needs a robust security and compliance framework that protects patient data and ensures agents operate within regulated bounds. That framework should include strict adherence to common industry standards like SOC 2 and HIPAA, but should also have processes built in for bias testing, protected health information redaction, and data retention.
These security safeguards don’t just check compliance boxes. They form the backbone of a trustworthy system that can ensure every interaction is managed at a level patients and providers expect.
The healthcare industry doesn’t need more AI hype. It needs reliable AI infrastructure. In the case of agentic AI, trust won’t be earned as much as it will be engineered.
#agent#Agentic AI#agents#ai#ai agent#AI AGENTS#AI Infrastructure#appointment scheduling#approach#autonomous#Bias#Building#burnout#call Centers#clinical#communication#compliance#creativity#data#diabetes#Drift#Engineer#engineering#Facts#focus#form#framework#Graph#Hallucination#hallucinations
0 notes
Text
#graphrag#esg sustainability#semantic graph model#esg domains#knowledge graph llm#esg and nlp#graph rag llm
0 notes
Text
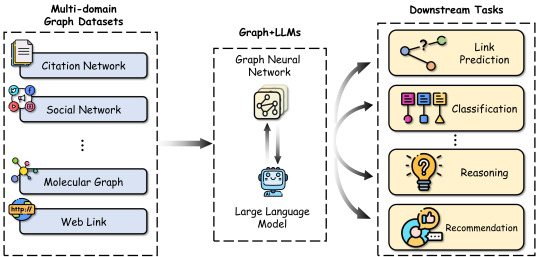
How can LLMs help improve graph-related tasks
2 notes
·
View notes
Text

Structured Data, Schema, and the Future of AI-Readable Content
Introduction
As AI-driven platforms like Google SGE, ChatGPT, Bing Copilot, and voice assistants reshape how content is discovered and presented, structured data has become the backbone of visibility.
In a world where language models rely on context and structure—not just keywords—schema markup is your key to making content machine-readable, trustworthy, and reference-worthy.
This article breaks down how structured data works, why it matters more than ever in the era of LLMs, and how B2B companies can implement schema to boost AI discoverability and authority.
What Is Structured Data?
Structured data refers to a standardized format (typically using Schema.org) that tells search engines and AI tools what your content means, not just what it says.
It helps algorithms:
Identify page content (e.g., “This is a service,” “This is a review,” “This is a location”)
Understand entities like businesses, people, products, and events
Connect your brand to broader knowledge graphs
The format is often implemented in JSON-LD, embedded in the HTML of a web page.
Why Structured Data Is Crucial for AI Visibility
✅ 1. It Enables AI Summarization and Citations
AI tools use structured data to:
Understand the context and credibility of a page
Attribute content to specific entities or people
Create summaries and comparisons with higher confidence
Without structured data, your content might not be indexed properly by LLMs, even if it's well-written.
✅ 2. It Boosts Google SGE & Rich Result Inclusion
Google’s AI-generated results frequently reference content that:
Uses schema for clarity
Provides clear answers to common questions
Is linked to recognized entities (brands, people, products)
Schema improves your chances of appearing in:
Featured snippets
SGE-generated answer panels
Knowledge panels and entity boxes
✅ 3. It Future-Proofs Your Website for Voice and Chat Interfaces
AI assistants (e.g., Google Assistant, Alexa, Siri, ChatGPT voice) need structured inputs to:
Provide accurate answers
Reference brands confidently
Handle follow-up questions
Structured data acts as a translation layer between your website and AI interfaces.
Core Schema Types Every B2B Business Should Use
Schema TypePurposeOrganizationDefines your business name, logo, contact info, social linksLocalBusinessAdds NAP info, service areas, hours for Google Maps/SGEProduct/ServiceDescribes offerings, use cases, benefits, pricesFAQPageMarks up frequently asked questions and answersReview/RatingSurfaces testimonials or case study summariesArticle/BlogPostingClarifies authorship, publish date, topicWebPageDefines canonical URL and page-specific detailsPersonUseful for expert-driven brands (show bios, credentials)
Pro Tip: Use tools like Schema Markup Validator to test your structured data.
Examples of Structured Data in Practice
✅ B2B Cybersecurity Firm:
Uses:
Organization schema for company identity
Service schema for penetration testing, compliance audits
FAQPage schema for “What is SOC 2?” questions
Result: Higher inclusion in AI responses when users ask about “best SOC 2 auditors for fintech companies.”
✅ SaaS Vendor for Logistics:
Uses:
Product schema for software features
Review schema to showcase customer feedback
LocalBusiness schema to target regional clients
Result: Appearances in SGE panels and Bing summaries for “supply chain SaaS providers near me.”
How to Implement Structured Data on Your Website
🛠️ 1. Add JSON-LD Markup to Your Header
Embed schema code in the <head> section or body of relevant pages.
Example:
jsonCopy
Edit
{ "@context": "https://schema.org", "@type": "Organization", "name": "Acme B2B Solutions", "url": "https://www.acmeb2b.com", "logo": "https://www.acmeb2b.com/logo.png", "sameAs": [ "https://www.linkedin.com/company/acmeb2b", "https://twitter.com/acmeb2b" ], "contactPoint": { "@type": "ContactPoint", "telephone": "+1-800-123-4567", "contactType": "Customer Service" } }
🧱 2. Use a Schema Plugin (for WordPress or CMS Sites)
Top options:
Rank Math (WordPress)
Yoast SEO (includes basic schema)
Schema App Structured Data (enterprise-level)
✍️ 3. Mark Up Content Types with Clear Hierarchy
Use FAQPage schema only when the content is truly Q&A format
Add author, datePublished, and headline to all blog posts
Be consistent in naming and referencing your company and people
Schema for AI vs. Schema for SERPs
Traditional schema focused on:
Winning rich snippets
Increasing CTR from search
AI-era schema focuses on:
Making content machine-readable
Increasing inclusion in summaries
Establishing entity clarity and credibility
Both are still important—but the balance is shifting.
Common Mistakes to Avoid
❌ Using outdated schema types (e.g., Blog instead of BlogPosting)
❌ Marking up in-line content incorrectly (like a paragraph as a product)
❌ Leaving out schema on “about,” “services,” and “case study” pages
❌ Over-optimizing with spammy structured data
❌ Not linking schema to real-world entities (e.g., Wikipedia, LinkedIn)
Future Trends in Structured Data and AI
TrendWhy It MattersEntity linkingAI relies on connections to known data sets (Wikidata, Freebase)Voice search schemaSpeakable markup helps with AI-read audio responsesReal-time updatesSchema signals may be refreshed more often by LLMsMultimodal dataStructured metadata for images, video, and audio will gain importanceContent provenanceSchema for authorship and source credibility will help combat AI misinformation
Conclusion
As generative AI becomes the front door to your B2B brand, structured data is no longer optional—it’s essential.
If you want ChatGPT, Bing Copilot, and SGE to:
Understand what your company does
Include you in summaries
Recommend your solutions to potential buyers
…you need to give them clean, clear, and complete schema markup to work with.
This is how you move from being searchable to being summarized.
0 notes
Text
The Future of SEO: Embracing Generative Engine Optimization

As the digital world continues to evolve, traditional SEO strategies are quickly becoming outdated. Enter Generative Engine Optimization—a forward-thinking approach that adapts to how search engines now generate answers rather than simply index content. At ThatWare LLP, we’re pioneering this cutting-edge strategy to help brands future-proof their digital presence.
What is Generative Engine Optimization?
Generative Engine Optimization (GEO) refers to the practice of optimizing digital content for AI-powered, generative search engines like ChatGPT, Google SGE, and other LLM-integrated platforms. Unlike legacy SEO, where keyword-stuffing and backlinks were enough, GEO focuses on context, intent, and machine-readable authority.
Search is no longer just about keywords—it’s about conversational relevance and AI comprehension.
Why Traditional SEO Isn’t Enough Anymore
Traditional SEO was designed for algorithms that crawl, index, and rank based on technical metrics like keyword density, metadata, and backlinks. But now, users are increasingly turning to generative search engines that offer human-like, context-aware responses to their queries.
These AI-driven platforms generate answers on the fly—meaning if your content isn’t structured for generative comprehension, you're invisible.
What is Generative Search Optimization?
Generative Search Optimization (GSO) is a refined branch of GEO that focuses specifically on tailoring content for AI search experiences. It involves:
Structuring content semantically
Using natural language to answer intent-driven queries
Feeding high-quality datasets and context to LLMs
Building topical authority and interlinking logically
Optimizing for zero-click, AI-generated results
At ThatWare LLP , we incorporate advanced AI, NLP, and data science to ensure your content doesn't just rank—but gets referenced, summarized, and preferred by generative search models.
Generative Search Engine SEO: A New Ranking Paradigm
Generative Search Engine SEO bridges the gap between traditional technical SEO and the new wave of conversational search. It’s not just about getting found—it’s about being the source of the answer. Our AI-driven SEO solutions make your content:
Machine-readable and LLM-friendly
Conversationally relevant for AI prompts
Entity-optimized using knowledge graphs and schema
Authoritative through semantic topic modeling
We help your brand be the final answer, not just a blue link.
How ThatWare Leads in Generative Engine Optimization
At ThatWare LLP , we combine AI-powered SEO, semantic web technologies, and machine learning to create a powerful foundation for success in the generative web.
Our proprietary strategies ensure your content aligns with how AI understands and delivers information. With over a decade of innovation in AI SEO, we’re redefining what it means to rank in the age of intelligent search.
Final Thoughts
As generative AI continues to disrupt the search landscape, only those who adapt will thrive. Generative Engine Optimization, Generative Search Optimization, and Generative Search Engine SEO are not just buzzwords—they're the future of discoverability.
0 notes
Text
Semantic Knowledge Graphing Market Size, Share, Analysis, Forecast, and Growth Trends to 2032: Transforming Data into Knowledge at Scale
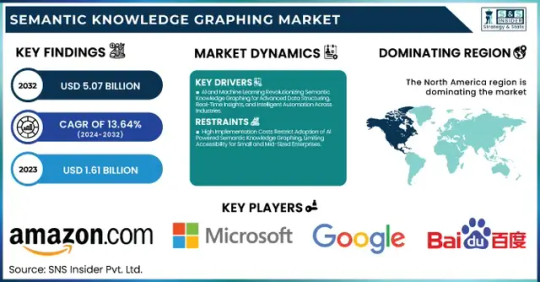
The Semantic Knowledge Graphing Market was valued at USD 1.61 billion in 2023 and is expected to reach USD 5.07 billion by 2032, growing at a CAGR of 13.64% from 2024-2032.
The Semantic Knowledge Graphing Market is rapidly evolving as organizations increasingly seek intelligent data integration and real-time insights. With the growing need to link structured and unstructured data for better decision-making, semantic technologies are becoming essential tools across sectors like healthcare, finance, e-commerce, and IT. This market is seeing a surge in demand driven by the rise of AI, machine learning, and big data analytics, as enterprises aim for context-aware computing and smarter data architectures.
Semantic Knowledge Graphing Market Poised for Strategic Transformation this evolving landscape is being shaped by an urgent need to solve complex data challenges with semantic understanding. Companies are leveraging semantic graphs to build context-rich models, enhance search capabilities, and create more intuitive AI experiences. As the digital economy thrives, semantic graphing offers a foundation for scalable, intelligent data ecosystems, allowing seamless connections between disparate data sources.
Get Sample Copy of This Report: https://www.snsinsider.com/sample-request/6040
Market Keyplayers:
Amazon.com Inc. (Amazon Neptune, AWS Graph Database)
Baidu, Inc. (Baidu Knowledge Graph, PaddlePaddle)
Facebook Inc. (Facebook Graph API, DeepText)
Google LLC (Google Knowledge Graph, Google Cloud Dataproc)
Microsoft Corporation (Azure Cosmos DB, Microsoft Graph)
Mitsubishi Electric Corporation (Maisart AI, MELFA Smart Plus)
NELL (Never-Ending Language Learner, NELL Knowledge Graph)
Semantic Web Company (PoolParty Semantic Suite, Semantic Middleware)
YAGO (YAGO Knowledge Base, YAGO Ontology)
Yandex (Yandex Knowledge Graph, Yandex Cloud ML)
IBM Corporation (IBM Watson Discovery, IBM Graph)
Oracle Corporation (Oracle Spatial and Graph, Oracle Cloud AI)
SAP SE (SAP HANA Graph, SAP Data Intelligence)
Neo4j Inc. (Neo4j Graph Database, Neo4j Bloom)
Databricks Inc. (Databricks GraphFrames, Databricks Delta Lake)
Stardog Union (Stardog Knowledge Graph, Stardog Studio)
OpenAI (GPT-based Knowledge Graphs, OpenAI Embeddings)
Franz Inc. (AllegroGraph, Allegro CL)
Ontotext AD (GraphDB, Ontotext Platform)
Glean (Glean Knowledge Graph, Glean AI Search)
Market Analysis
The Semantic Knowledge Graphing Market is transitioning from a niche segment to a critical component of enterprise IT strategy. Integration with AI/ML models has shifted semantic graphs from backend enablers to core strategic assets. With open data initiatives, industry-standard ontologies, and a push for explainable AI, enterprises are aggressively adopting semantic solutions to uncover hidden patterns, support predictive analytics, and enhance data interoperability. Vendors are focusing on APIs, graph visualization tools, and cloud-native deployments to streamline adoption and scalability.
Market Trends
AI-Powered Semantics: Use of NLP and machine learning in semantic graphing is automating knowledge extraction and relationship mapping.
Graph-Based Search Evolution: Businesses are prioritizing semantic search engines to offer context-aware, precise results.
Industry-Specific Graphs: Tailored graphs are emerging in healthcare (clinical data mapping), finance (fraud detection), and e-commerce (product recommendation).
Integration with LLMs: Semantic graphs are increasingly being used to ground large language models with factual, structured data.
Open Source Momentum: Tools like RDF4J, Neo4j, and GraphDB are gaining traction for community-led innovation.
Real-Time Applications: Event-driven semantic graphs are now enabling real-time analytics in domains like cybersecurity and logistics.
Cross-Platform Compatibility: Vendors are prioritizing seamless integration with existing data lakes, APIs, and enterprise knowledge bases.
Market Scope
Semantic knowledge graphing holds vast potential across industries:
Healthcare: Improves patient data mapping, drug discovery, and clinical decision support.
Finance: Enhances fraud detection, compliance tracking, and investment analysis.
Retail & E-Commerce: Powers hyper-personalized recommendations and dynamic customer journeys.
Manufacturing: Enables digital twins and intelligent supply chain management.
Government & Public Sector: Supports policy modeling, public data transparency, and inter-agency collaboration.
These use cases represent only the surface of a deeper transformation, where data is no longer isolated but intelligently interconnected.
Market Forecast
As AI continues to integrate deeper into enterprise functions, semantic knowledge graphs will play a central role in enabling contextual AI systems. Rather than just storing relationships, future graphing solutions will actively drive insight generation, data governance, and operational automation. Strategic investments by leading tech firms, coupled with the rise of vertical-specific graphing platforms, suggest that semantic knowledge graphing will become a staple of digital infrastructure. Market maturity is expected to rise rapidly, with early adopters gaining a significant edge in predictive capability, data agility, and innovation speed.
Access Complete Report: https://www.snsinsider.com/reports/semantic-knowledge-graphing-market-6040
Conclusion
The Semantic Knowledge Graphing Market is no longer just a futuristic concept—it's the connective tissue of modern data ecosystems. As industries grapple with increasingly complex information landscapes, the ability to harness semantic relationships is emerging as a decisive factor in digital competitiveness.
About Us:
SNS Insider is one of the leading market research and consulting agencies that dominates the market research industry globally. Our company's aim is to give clients the knowledge they require in order to function in changing circumstances. In order to give you current, accurate market data, consumer insights, and opinions so that you can make decisions with confidence, we employ a variety of techniques, including surveys, video talks, and focus groups around the world.
Contact Us:
Jagney Dave - Vice President of Client Engagement
Phone: +1-315 636 4242 (US) | +44- 20 3290 5010 (UK)
#Semantic Knowledge Graphing Market#Semantic Knowledge Graphing Market Share#Semantic Knowledge Graphing Market Scope#Semantic Knowledge Graphing Market Trends
1 note
·
View note
Text
Build real-time knowledge graph for documents with LLM
https://cocoindex.io/blogs/knowledge-graph-for-docs/
0 notes